Maintain #277
已結束8/13 凌晨3點 PRD ES-02 容器崩潰
100%
概述
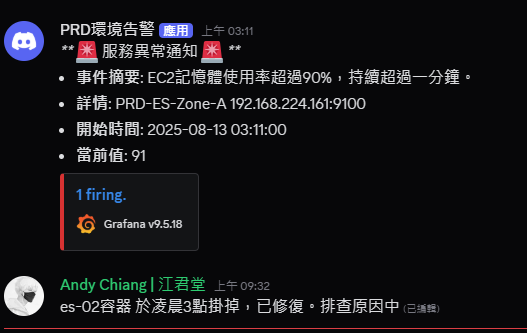
8/13 凌晨3點 PRD ES-02 容器崩潰,該節點為主節點,導致訪問 503。目前修復後,主節點已改為 ES-01
檔案
是由 andy chiang 於 7 個月 前更新 · 已被編輯
- 檔案 clipboard-202508130948-xsykp.png clipboard-202508130948-xsykp.png 已新增
- 檔案 clipboard-202508130949-zooe4.png clipboard-202508130949-zooe4.png 已新增
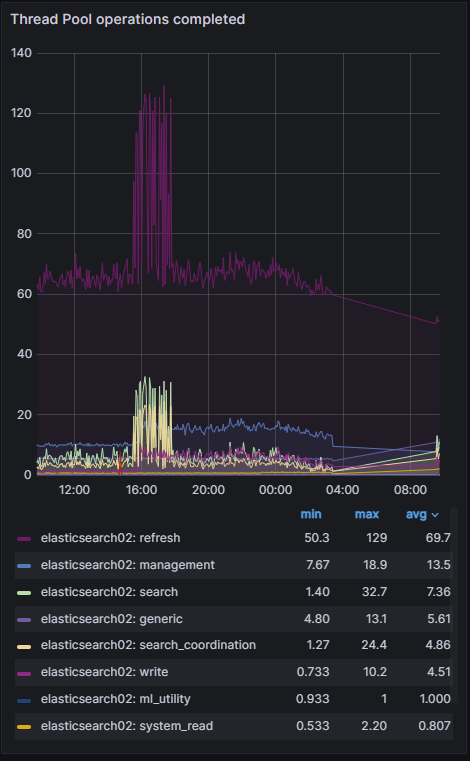
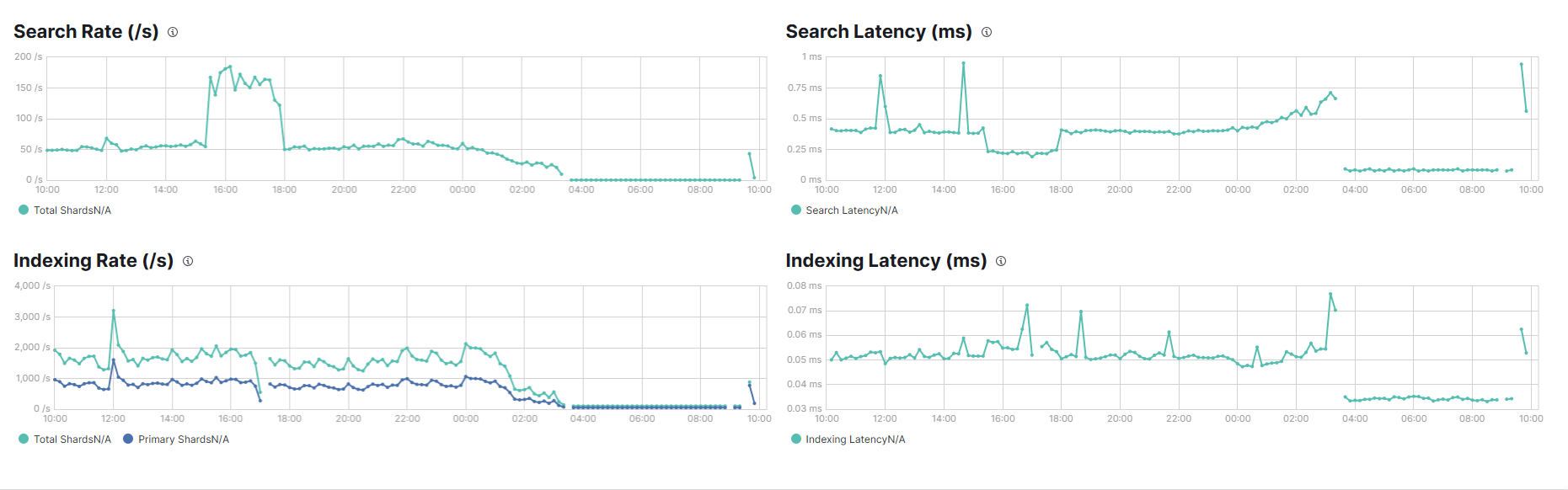
- 其他時段之異常高峰(大約 12:00–16:00)
refresh 線(紫色)在這段時間飆到 max ≈ 140/s,平時平均大概 60–70/s。
refresh 線持續高於正常值,代表這段時間索引的段落(segments)被頻繁刷新,這會增加磁碟 I/O 與 CPU 使用。
在同時間,search、search_coordination、write 等也有同步小幅上升,但幅度遠低於 refresh。
可能原因
大量的寫入/更新請求(會觸發 refresh)
ILM 或索引管理任務(rollover、mapping 更新)間接導致大量 refresh
你的 .ds-* index 如果因為 ILM policy 失敗,不斷重試 rollover,也可能帶來額外 refresh 負載
是由 andy chiang 於 7 個月 前更新
- 檔案 clipboard-202508131000-lxz2r.png clipboard-202508131000-lxz2r.png 已新增
- 完成百分比 從 0 變更為 20

記憶體平時維持 88%左右,異常時段有上升最高至 97%,導致容器無法負載
是由 andy chiang 於 7 個月 前更新 · 已被編輯
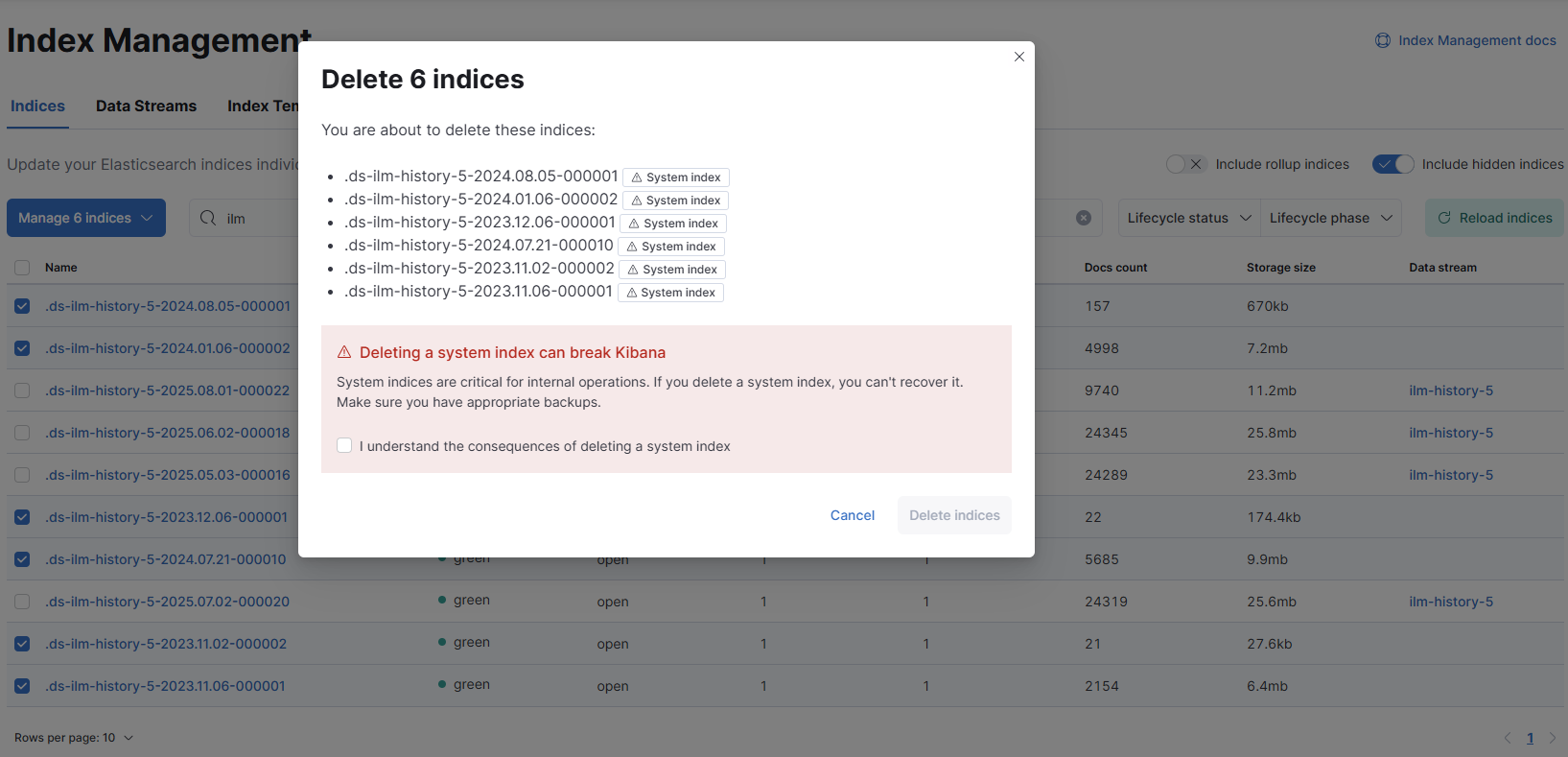
部分歷史資料沒有綁定政策,刪除避免後患
{"type": "server", "timestamp": "2025-08-13T00:53:20,527Z", "level": "ERROR", "component": "o.e.x.i.IndexLifecycleRunner", "cluster.name": "docker-cluster", "node.name": "elasticsearch02", "message": "policy [ilm-history-ilm-policy] for index [.ds-ilm-history-5-2024.08.05-000001] failed on step [{"phase":"hot","action":"rollover","name":"check-rollover-ready"}]. Moving to ERROR step", "cluster.uuid": "DJSB9UpMT_e_apj6t2GWxQ", "node.id": "4PITO2JZRJWMNsZ4QVI3Ig" ,
是由 marlboro chu 於 7 個月 前更新
- 檔案 clipboard-202508131414-o7dbc.png clipboard-202508131414-o7dbc.png 已新增
- 檔案 clipboard-202508131414-kpix1.png clipboard-202508131414-kpix1.png 已新增
- 檔案 clipboard-202508131415-qxhbx.png clipboard-202508131415-qxhbx.png 已新增
主要為 elasticsearch03 突然的停止,而剩下的 elasticsearch02 和 elasticsearch01 仍活著,但選不出 master,故造成整個叢集無法使用。
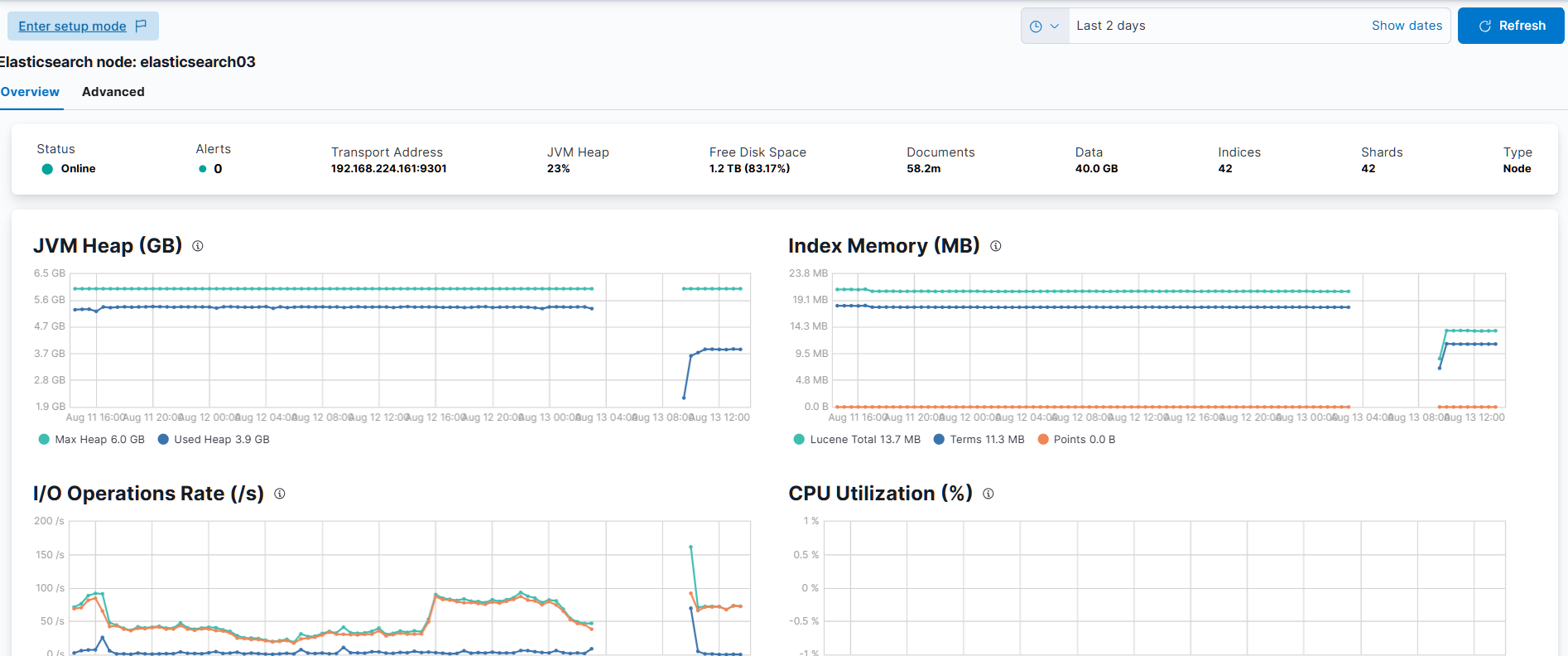
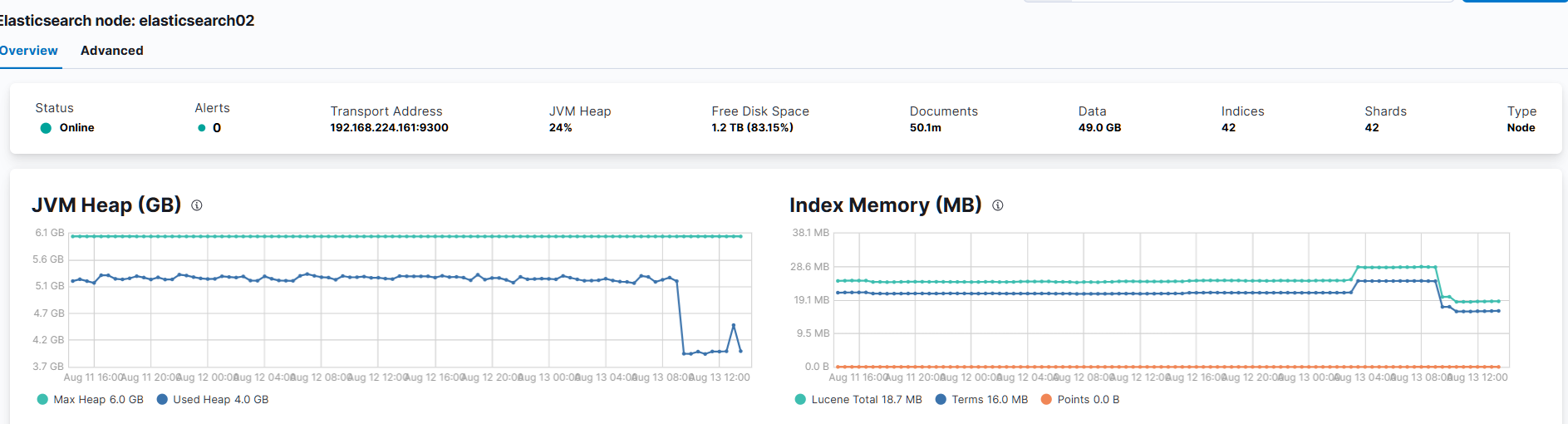
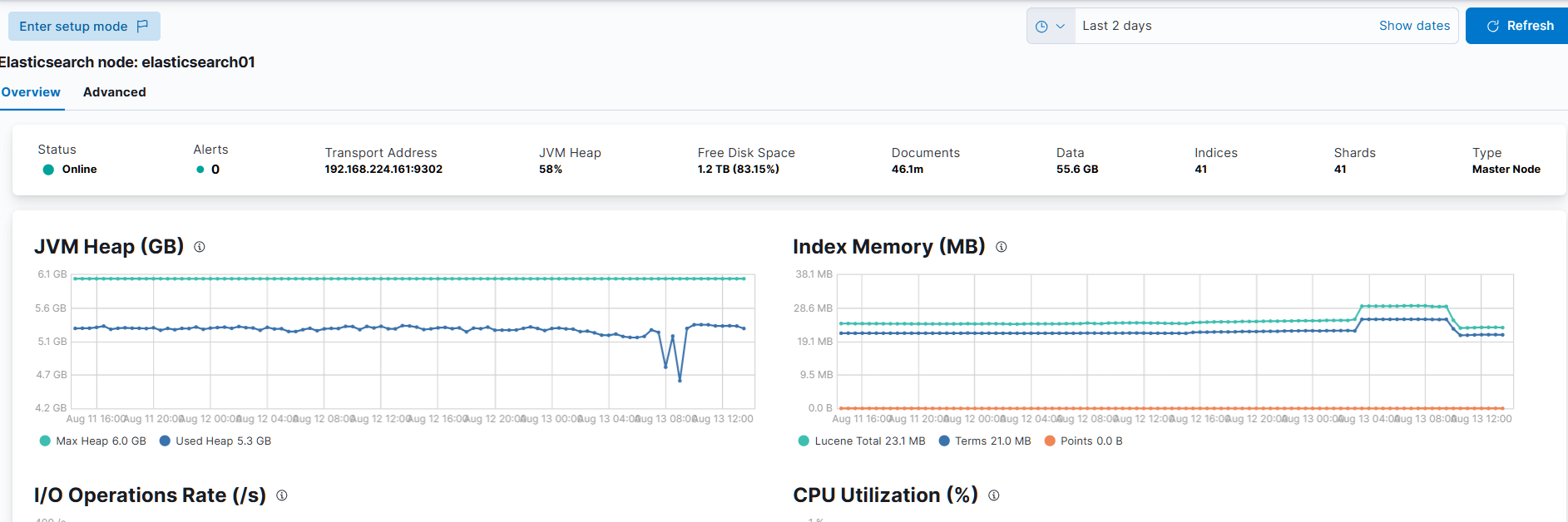
是由 marlboro chu 於 7 個月 前更新
當有六台 Elasticsearch 節點,其中三台設定了 cluster.initial_master_nodes: elasticsearch01, elasticsearch02, elasticsearch03,而另外三台沒有設定,且其他參數皆為預設值,當這三台設定了 cluster.initial_master_nodes 的 master-eligible 节点之一掛掉,導致整個叢集無法使用,最主要原因是:
主要原因:cluster.initial_master_nodes 只用於集群啟動引導,且必須在所有 master-eligible 節點中一致設定
cluster.initial_master_nodes 是用來「啟動叢集(cluster bootstrap)」時,指定參與初始 master 選舉的 master-eligible 節點名單。這個設定只需要在所有 master-eligible 節點上保持一致且只在叢集初次啟動時使用。
若叢集已有運行且持續運作,cluster.initial_master_nodes 不應該保留在後續節點的配置中,且所有 master-eligible 節點都必須互相辨識且知道彼此,通常由 discovery.seed_hosts 負責節點發現。
如果只有三台 master-eligible 設定了 cluster.initial_master_nodes,另外三台沒有,代表這六台並非一致配置,而這種不一致會導致叢集形成混亂或錯誤行為。
如果該配置沒被移除,當其中一台原本設定了 cluster.initial_master_nodes 的 master-eligible 節點掛掉,其它節點可能因無法成功完成 quorum bootstrap,造成叢集無法選出 master,進而導致整個叢集無法正常工作。
更糟的是,過時或不正確地保留 cluster.initial_master_nodes 配置在非啟動階段的節點,會導致「多個獨立集群」或節點間無法有效溝通。
簡單說,導致叢集無法用的關鍵點
cluster.initial_master_nodes 只用於首次啟動 bootstrap,且必須在所有 master-eligible 節點中一致設定。
如果在已有叢集運行後仍在部分節點保留此設定,會導致節點間協調問題。
設定不一致時,節點可能無法達成 quorum 選舉 master,尤其當已設定的 master-eligible 節點之一掛掉時就導致無法完成選主。
其結果是整個叢集出現「無法選出 master」、「集群不可用」的狀況。
正確的做法建議
啟動新叢集時,在所有 master-eligible 節點的配置文件中以相同方式設定 cluster.initial_master_nodes。
叢集成功組建後,移除所有節點中的 cluster.initial_master_nodes 配置。
新加入的節點只需設定 discovery.seed_hosts 以發現 master 及其它節點。
確保所有 master-eligible 節點有正確且一致的發現設定,並且至少有過半(master quorum)節點可用。
是由 andy chiang 於 7 個月 前更新
- 檔案 clipboard-202508141634-de2de.png clipboard-202508141634-de2de.png 已新增
- 完成百分比 從 20 變更為 70
8/14 凌晨3點再度 mem 過高,服務異常。報錯內容出現:
java.lang.IllegalStateException: index [.monitoring-es-7-2025.08.14/2Zb2m6aYQ5GZ-_BqBaVM4g] version not supported: 7.17.21 the node version is: 7.17.13
叢集內出現版本不一致問題,導致 master 選舉無法正常進行,叢集崩潰。經排查後仍無效修復,必須將 volume 初始化重新建立。
8/14 下午已將 es 叢集重建, volume 改為 new-volume 資料夾,並重新優化 yaml 設定檔確保 master 選舉正常運作。

是由 andy chiang 於 7 個月 前更新 · 已被編輯
後規劃將一台拆成四台規格小的機器,採 2-2-1-1
當前配置與需求分析
現有配置:
2 台 c7i.4xlarge,vCPU: 16/台,Memory: 32 GiB/台,總 vCPU: 32,總 Memory: 64 GiB。
6 個 Elasticsearch 節點(假設均勻分配,每台 c7i.4xlarge 運行 3 個節點),每節點約分配 10.67 GiB 記憶體(64 GiB ÷ 6)。
價格(新加坡地區):0.8232 USD/小時/台 × 2 = 1.6464 USD/小時,月 1,202.13 USD,年 14,422.46 USD。
目標配置:
使用 r7i.large(vCPU: 2,Memory: 16 GiB/台),總記憶體需 ≥ 64 GiB,支持 6 個節點。
考慮成本、性能和資源分配,確定最佳台數。
假設:
每台 r7i.large 運行 1-2 個節點,確保 JVM 堆記憶體(例如 12 GiB/節點)與主機記憶體匹配。
不含儲存或其他費用,僅計算實例成本。
計算與比較
r7i.large 規格與分配
r7i.large:vCPU: 2,Memory: 16 GiB。
每台可支持 1-2 個節點:
1 節點:JVM 堆 12 GiB,留 4 GiB 系統。
2 節點:JVM 堆 6 GiB/節點,留 4 GiB 系統(較緊湊)。
候選方案
4 台 r7i.large(每台 1.5 節點平均)
總 Memory: 4 × 16 GiB = 64 GiB。
節點分配:每台 1-2 節點(例如 2-2-1-1 或 1-1-2-2)。
總 vCPU: 4 × 2 = 8。
價格:0.189 USD/小時/台 × 4 = 0.756 USD/小時。
月:0.756 × 730 = 551.88 USD。
年:0.756 × 8760 = 6,622.56 USD。
成本差異:月節省 1,202.13 - 551.88 = 650.25 USD(54%),年節省 7,799.90 USD(54%)。
5 台 r7i.large(每台 1.2 節點平均)
總 Memory: 5 × 16 GiB = 80 GiB。
節點分配:例如 1-1-1-1-2。
總 vCPU: 5 × 2 = 10。
價格:0.189 USD/小時/台 × 5 = 0.945 USD/小時。
月:0.945 × 730 = 689.85 USD。
年:0.945 × 8760 = 8,282.20 USD。
成本差異:月節省 1,202.13 - 689.85 = 512.28 USD(43%),年節省 6,140.26 USD(43%)。
6 台 r7i.large(每台 1 節點)
總 Memory: 6 × 16 GiB = 96 GiB。
節點分配:每台 1 節點。
總 vCPU: 6 × 2 = 12。
價格:0.189 USD/小時/台 × 6 = 1.134 USD/小時。
月:1.134 × 730 = 827.82 USD。
年:1.134 × 8760 = 9,935.84 USD。
成本差異:月節省 1,202.13 - 827.82 = 374.31 USD(31%),年節省 4,486.62 USD(31%)。
儲存成本(假設)
每台 100GB gp3(0.1 USD/GB-月):
原配置:2 × 100GB = 20 USD/月。
4 台:400GB = 40 USD/月。
5 台:500GB = 50 USD/月。
6 台:600GB = 60 USD/月。
總成本:
原配置:1,202.13 + 20 = 1,222.13 USD/月。
4 台:551.88 + 40 = 591.88 USD/月。
5 台:689.85 + 50 = 739.85 USD/月。
6 台:827.82 + 60 = 887.82 USD/月。
節省(含儲存):
4 台:630.25 USD/月(52%),年 7,563.00 USD。
5 台:482.28 USD/月(39%),年 5,787.36 USD。
6 台:334.31 USD/月(27%),年 4,011.72 USD。
最佳方案建議
推薦:4 台 r7i.large
理由:
總 Memory (64 GiB) 匹配原配置,支持 6 節點(例如 2-2-1-1 分配)。
每節點可分配 10-12 GiB 堆記憶體,符合 Elasticsearch 需求。
成本最低(月 591.88 USD,年 7,102.56 USD),節省 52%(含儲存)。
vCPU (8) 減少但足以支持輕負載,適合記憶體密集任務。
是由 andy chiang 於 約 2 個月 前更新
案例總結:PRD ES-02 容器崩潰與叢集失效事件分析
一、 事件背景
時間: 2025年8月13日 凌晨 03:00
現象: PRD ES-02 節點崩潰,導致整個叢集出現 503 錯誤(服務不可用)。
受影響範圍: 搜尋服務、監控數據寫入。
二、 事件經過與關鍵轉折
- 第一次崩潰 (8/13 凌晨)
現象: 主節點 ES-02 記憶體飆升至 97% 後容器崩潰。
初步處理: 重啟服務,並將主節點暫時轉移至 ES-01。
排查發現:
指標異常: 凌晨 3 點正是 FLDS 任務運作時間,Refresh 指標從 60/s 飆升至 140/s。
管理錯誤: ILM(索引生命週期管理)政策在處理 .ds-ilm-history 時失敗並不斷重試,產生額外負載。 - 叢集無法選主 (Marlboro 的深度分析)
問題: 當 ES-03 停機時,剩餘的 ES-01、ES-02 無法選出 Master。
根因: 參數 cluster.initial_master_nodes 設定錯誤。
該參數僅應用於「第一次啟動」叢集。
若在正式運行中仍保留此設定,且節點配置不一致(3台有設、3台沒設),會導致 Quorum(法定人數)計算錯誤,造成叢集崩潰後無法自行恢復。 - 第二次崩潰 (8/14 凌晨)
現象: 凌晨 3 點記憶體再度飆升,服務徹底崩潰。
發現新病灶: 日誌顯示版本不一致(7.17.21 vs 7.17.13)。
處置: 由於選舉邏輯已毀損且排查無效,決定初始化 Volume 並重建叢集,優化 YAML 設定。
三、 根因總結 (Root Cause Analysis)
資源瓶頸 (Memory Exhaustion):
凌晨 3 點的 FLDS 大量寫入任務導致 Refresh 頻率過高,記憶體從 88% 壓榨到 97% 導致 OOM (Out of Memory)。
配置錯誤 (Configuration Bug):
cluster.initial_master_nodes 長期錯誤保留,導致節點失效時,叢集無法達成共識進行選主。
版本不一致 (Version Mismatch):
叢集內節點版本細微差異(.21 與 .13),導致選舉機制與索引讀取出現 IllegalStateException。
管理任務負擔:
無效的 ILM 政策導致系統不斷嘗試 Rollover,消耗額外的 I/O 與 CPU。
四、 解決方案與後續行動 - 立即修復
重建叢集: 重新掛載 new-volume,確保所有節點版本統一(7.17.13)。
優化設定: 移除正式環境中的 initial_master_nodes,改用正確的 discovery.seed_hosts。
清理資料: 刪除未綁定政策的歷史索引,停止 ILM 的錯誤重試。 - 架構優化建議 (Andy Chiang 提案)
為了提高容錯能力並降低成本,建議將現有的「2 台大機器」拆分為「4 台小機器」:
原配置: 2 * c7i.4xlarge (32 vCPU/64GB) -> 集中度太高,一台掛掉就損失 50% 戰力。
新建議: 4 * r7i.large (8 vCPU/64GB)
優點: 節點分散在 4 台實體機(2-2-1-1 分配),容錯率更高。
節省: 預計每月節省約 $630 USD (52% 降幅)。 - 程式面重構 (Martin Zhuo 提案)
專案關聯: 開立 [#319 PRD FLDS 重構] 議題。
目標: 優化凌晨 3 點的寫入邏輯,降低對 ES 造成的 Refresh 壓力和記憶體衝擊。