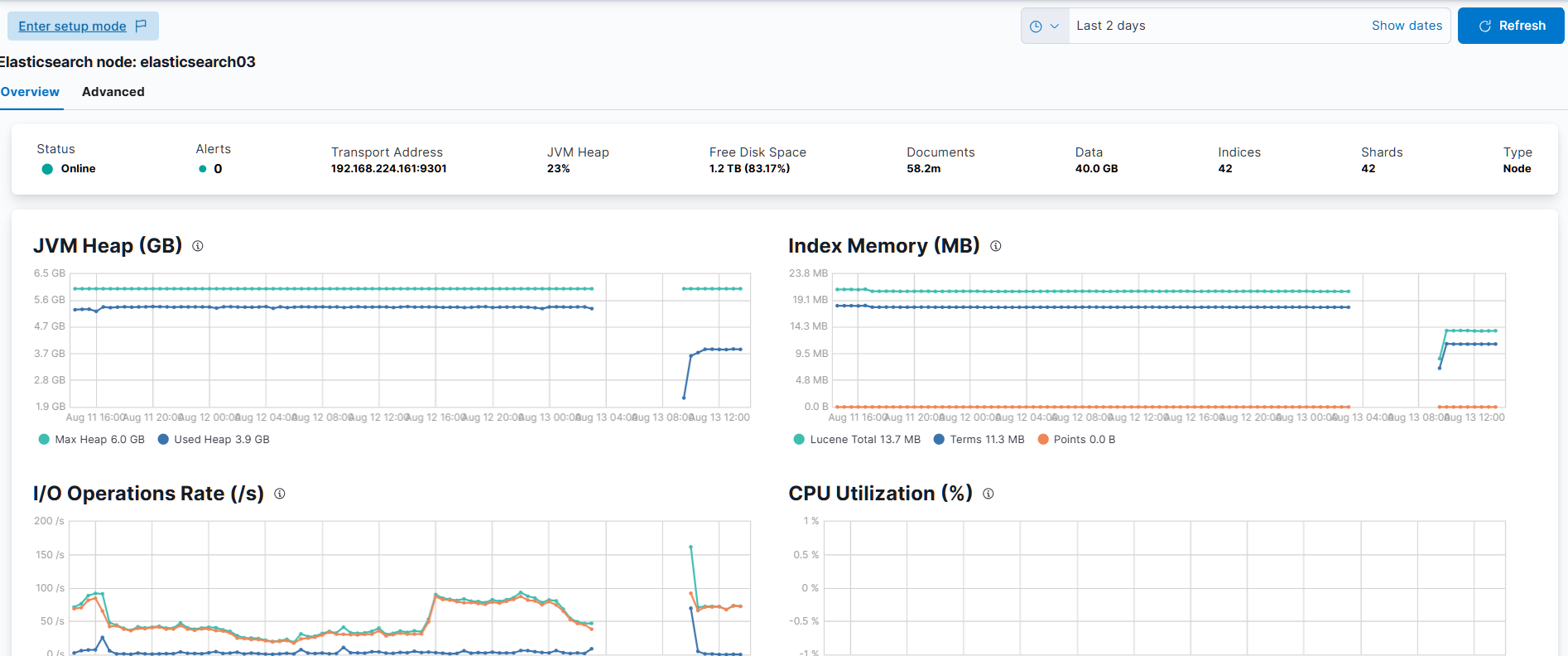
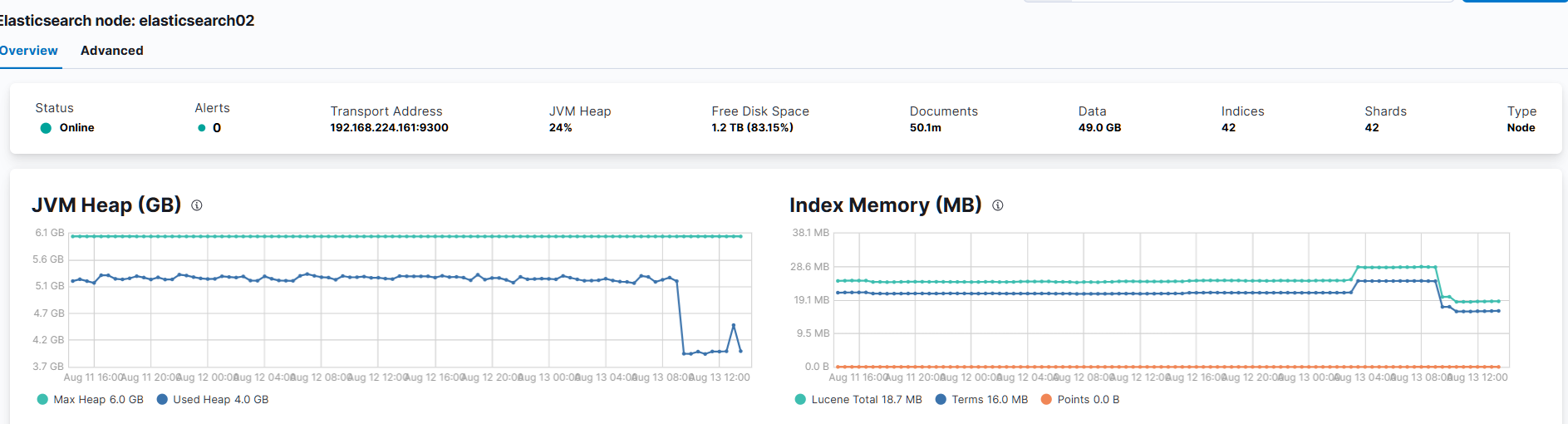
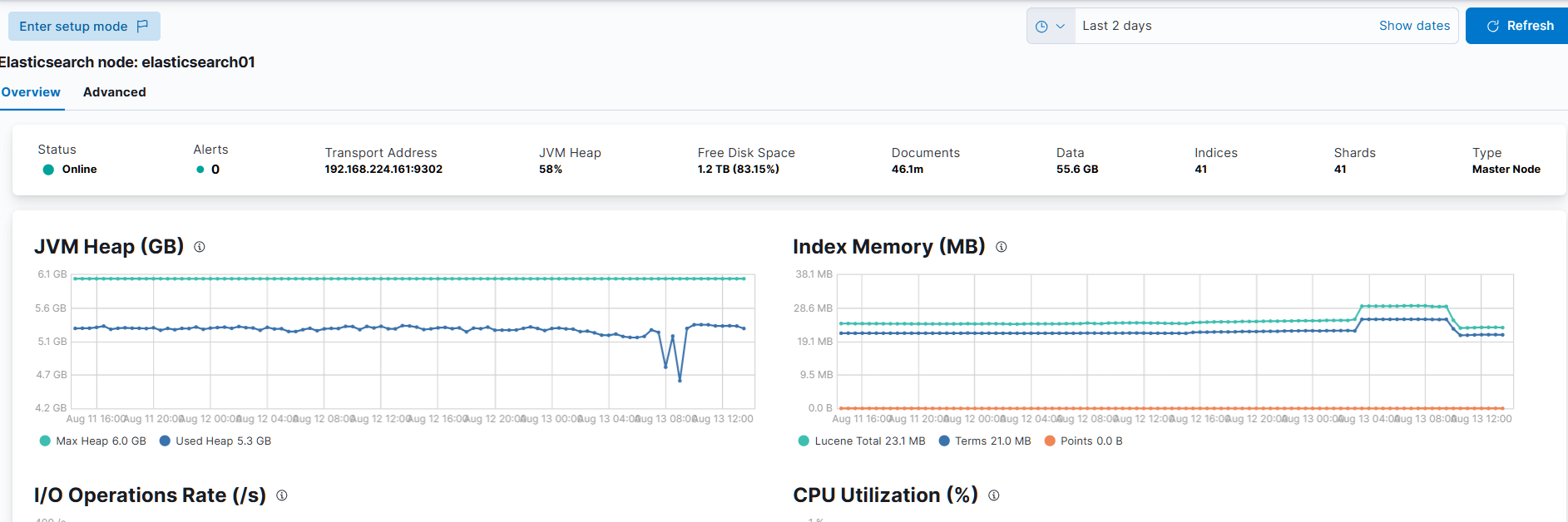
後規劃將一台拆成四台規格小的機器,採 2-2-1-1
當前配置與需求分析
現有配置:
2 台 c7i.4xlarge,vCPU: 16/台,Memory: 32 GiB/台,總 vCPU: 32,總 Memory: 64 GiB。
6 個 Elasticsearch 節點(假設均勻分配,每台 c7i.4xlarge 運行 3 個節點),每節點約分配 10.67 GiB 記憶體(64 GiB ÷ 6)。
價格(新加坡地區):0.8232 USD/小時/台 × 2 = 1.6464 USD/小時,月 1,202.13 USD,年 14,422.46 USD。
目標配置:
使用 r7i.large(vCPU: 2,Memory: 16 GiB/台),總記憶體需 ≥ 64 GiB,支持 6 個節點。
考慮成本、性能和資源分配,確定最佳台數。
假設:
每台 r7i.large 運行 1-2 個節點,確保 JVM 堆記憶體(例如 12 GiB/節點)與主機記憶體匹配。
不含儲存或其他費用,僅計算實例成本。
計算與比較
r7i.large 規格與分配
r7i.large:vCPU: 2,Memory: 16 GiB。
每台可支持 1-2 個節點:
1 節點:JVM 堆 12 GiB,留 4 GiB 系統。
2 節點:JVM 堆 6 GiB/節點,留 4 GiB 系統(較緊湊)。
候選方案
4 台 r7i.large(每台 1.5 節點平均)
總 Memory: 4 × 16 GiB = 64 GiB。
節點分配:每台 1-2 節點(例如 2-2-1-1 或 1-1-2-2)。
總 vCPU: 4 × 2 = 8。
價格:0.189 USD/小時/台 × 4 = 0.756 USD/小時。
月:0.756 × 730 = 551.88 USD。
年:0.756 × 8760 = 6,622.56 USD。
成本差異:月節省 1,202.13 - 551.88 = 650.25 USD(54%),年節省 7,799.90 USD(54%)。
5 台 r7i.large(每台 1.2 節點平均)
總 Memory: 5 × 16 GiB = 80 GiB。
節點分配:例如 1-1-1-1-2。
總 vCPU: 5 × 2 = 10。
價格:0.189 USD/小時/台 × 5 = 0.945 USD/小時。
月:0.945 × 730 = 689.85 USD。
年:0.945 × 8760 = 8,282.20 USD。
成本差異:月節省 1,202.13 - 689.85 = 512.28 USD(43%),年節省 6,140.26 USD(43%)。
6 台 r7i.large(每台 1 節點)
總 Memory: 6 × 16 GiB = 96 GiB。
節點分配:每台 1 節點。
總 vCPU: 6 × 2 = 12。
價格:0.189 USD/小時/台 × 6 = 1.134 USD/小時。
月:1.134 × 730 = 827.82 USD。
年:1.134 × 8760 = 9,935.84 USD。
成本差異:月節省 1,202.13 - 827.82 = 374.31 USD(31%),年節省 4,486.62 USD(31%)。
儲存成本(假設)
每台 100GB gp3(0.1 USD/GB-月):
原配置:2 × 100GB = 20 USD/月。
4 台:400GB = 40 USD/月。
5 台:500GB = 50 USD/月。
6 台:600GB = 60 USD/月。
總成本:
原配置:1,202.13 + 20 = 1,222.13 USD/月。
4 台:551.88 + 40 = 591.88 USD/月。
5 台:689.85 + 50 = 739.85 USD/月。
6 台:827.82 + 60 = 887.82 USD/月。
節省(含儲存):
4 台:630.25 USD/月(52%),年 7,563.00 USD。
5 台:482.28 USD/月(39%),年 5,787.36 USD。
6 台:334.31 USD/月(27%),年 4,011.72 USD。
最佳方案建議
推薦:4 台 r7i.large
理由:
總 Memory (64 GiB) 匹配原配置,支持 6 節點(例如 2-2-1-1 分配)。
每節點可分配 10-12 GiB 堆記憶體,符合 Elasticsearch 需求。
成本最低(月 591.88 USD,年 7,102.56 USD),節省 52%(含儲存)。
vCPU (8) 減少但足以支持輕負載,適合記憶體密集任務。