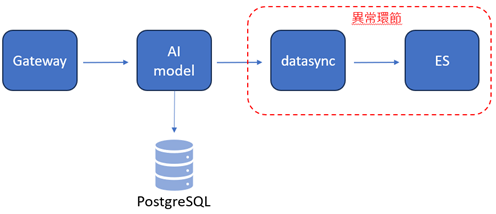
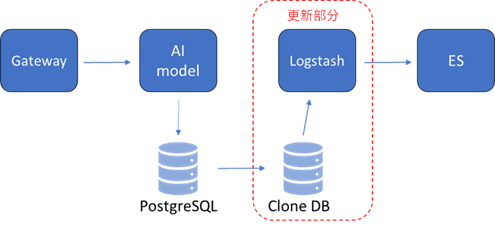
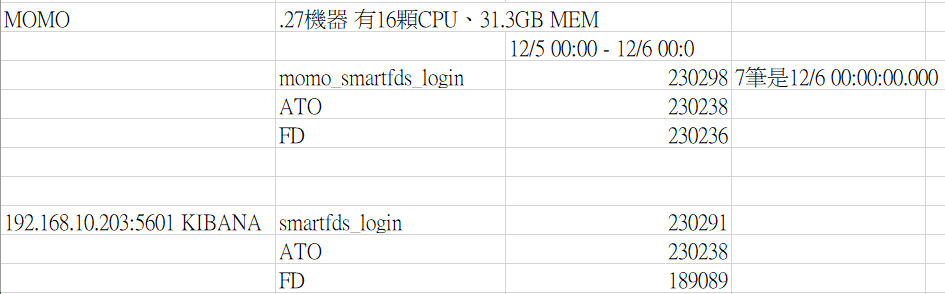
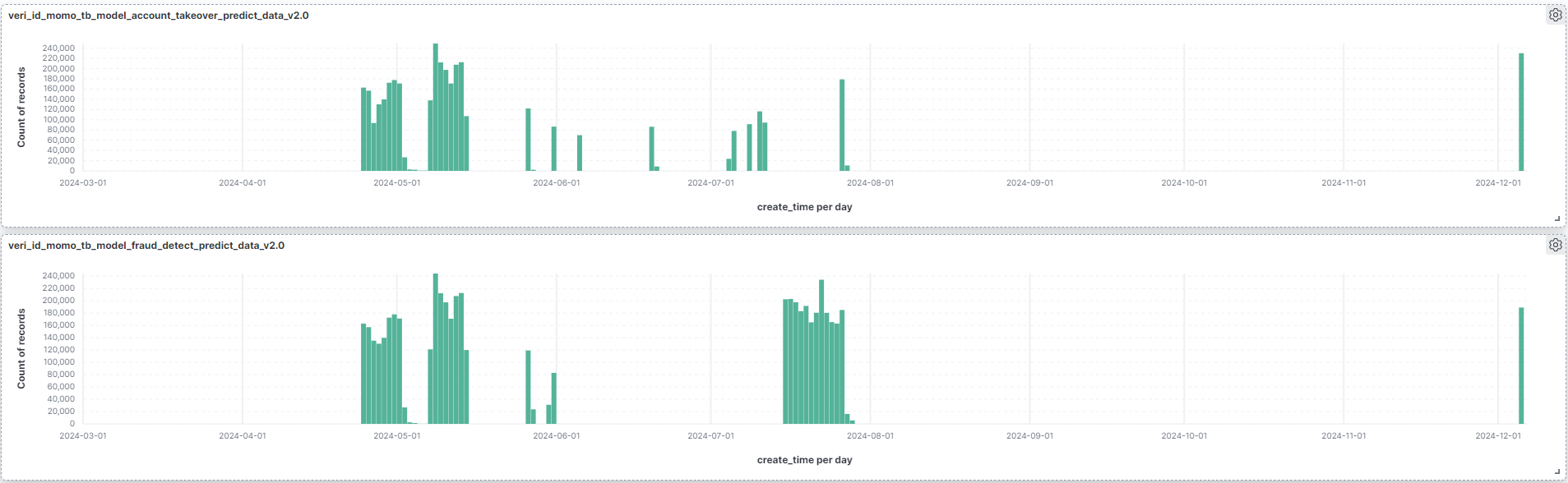
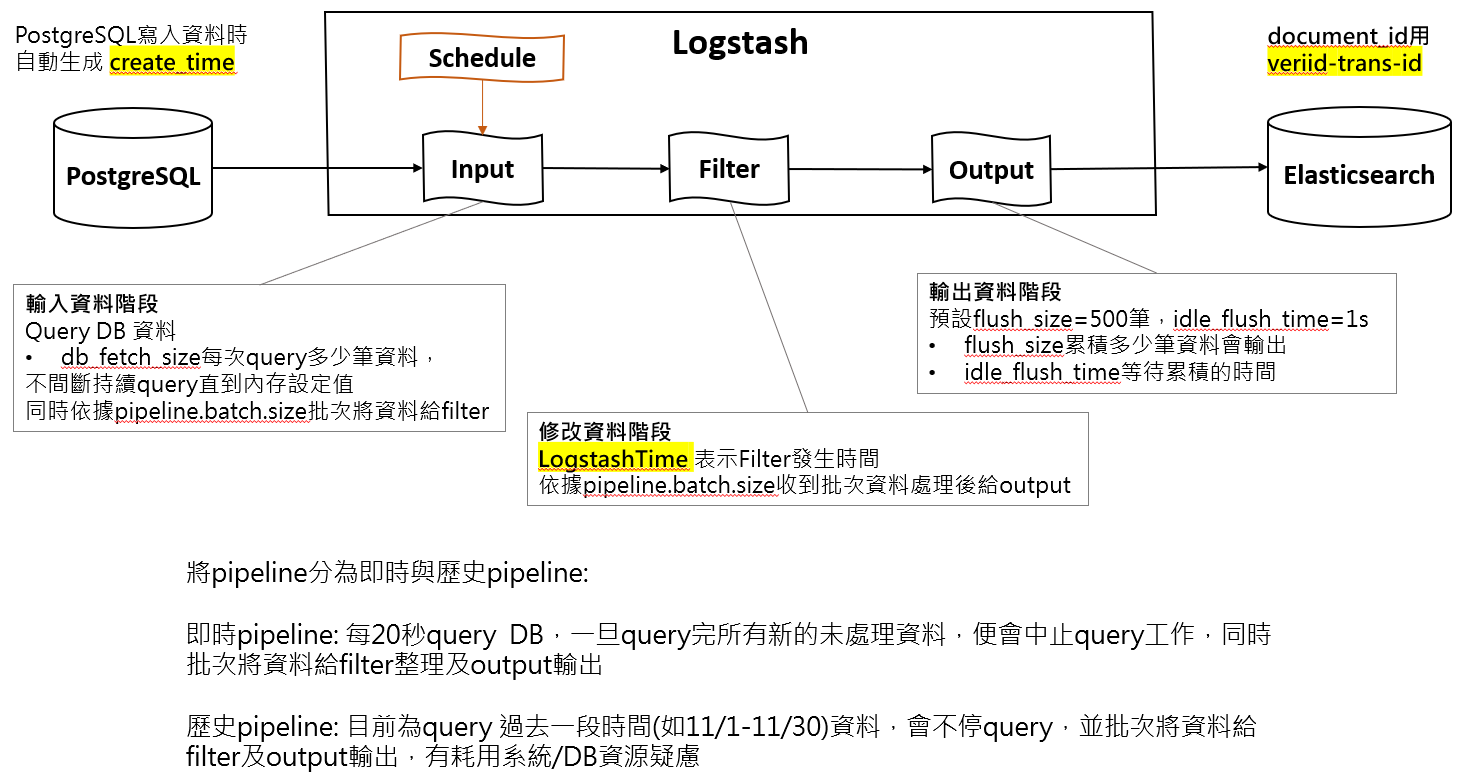
目前logstash設定:為從PG撈取11/1-11/30的所有資料,以每100筆批次讀取。
一旦數據提取完成,Logstash 將其放入內部事件處理管道中,而寫入ES以flush_size批次寫入。
預設flush_size=500筆,idle_flush_time=1s。flush_size 不能超过 Logstash 的 pipeline.batch.size,否则将以pipeline.batch.size为批量发送的大小。
pipeline.batch.size 是 Logstash 處理事件時的內部批量大小。
idle_flush_time是Logstash在累積到flush_size之前的等待時間,但超過了 idle_flush_time,Logstash 會強制執行批量操作
Logstash 並非一次性將整個查詢結果載入內存,而是按 db_fetch_size 分批讀取以減少內存壓力。
output {
elasticsearch {
flush_size => 20000
idle_flush_time => 10
在每次input->filter階段休息幾秒再執行filter->output,讓大量請求都等待兩秒再執行,並不能達到每次output都等待一段時間間隔的效果,因為query階段
filter {
ruby {
code => "sleep(2)" # 每次事件處理後延遲 2 秒
Logstash 的處理方式是 流式處理(streaming processing),並不會等待所有數據(例如你的 1 千萬筆 SQL 查詢結果)都讀取完畢後才進入後續的 filter 和 output 階段。相反,它會依據 pipeline.batch.size 等配置,分批處理數據。
Logstash 的處理流程
Input 插件
Input 插件(例如 JDBC 插件)負責從數據源(如數據庫)查詢數據。
查詢結果會被逐步送入 Logstash 的內部隊列,而不會一次性讀取所有數據。
Pipeline 緩衝機制
Logstash 的管道有內部緩衝,受 pipeline.batch.size 和 pipeline.workers 控制。
每次從內部隊列提取最多 pipeline.batch.size 條事件,進入 filter 和 output 階段。
Filter 和 Output 階段
提取的批次事件會經過 filter 插件處理。
經過過濾後的數據進入 output 插件(如 Elasticsearch 插件)進行寫入。
整個流程是以批次方式分段執行,直到所有數據都被處理。
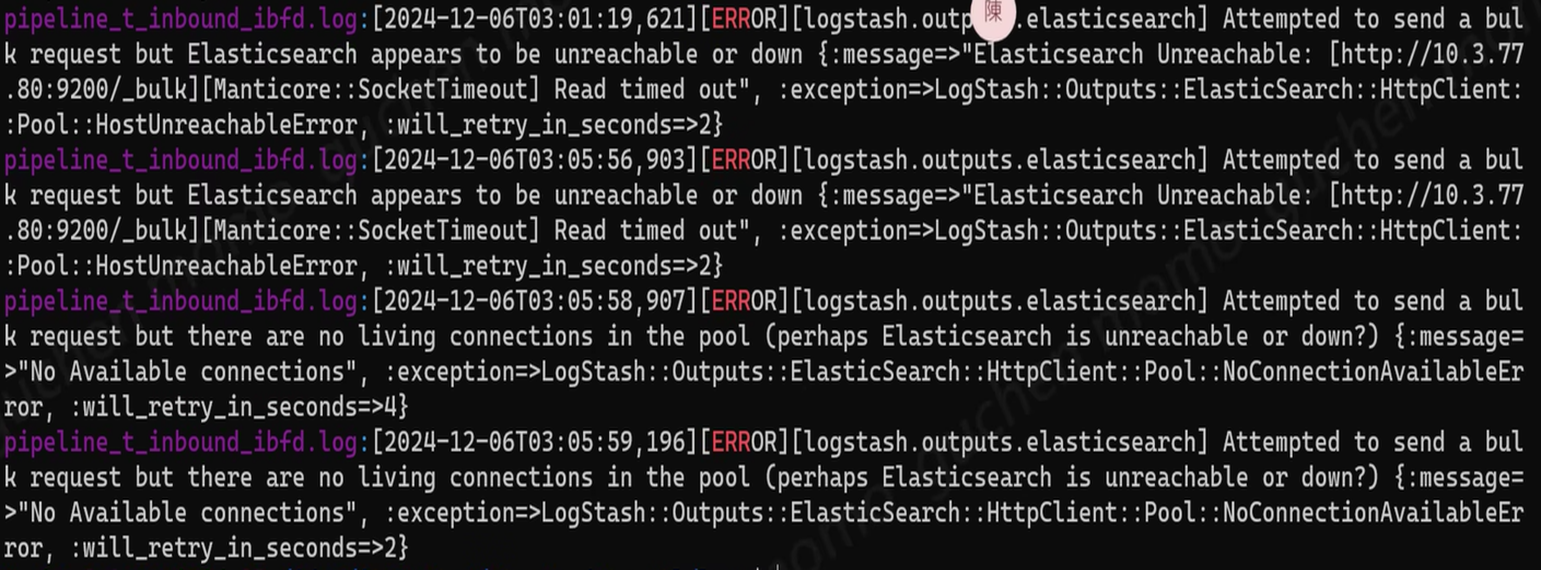
對應措施:
1.目前logstash等待連線5秒 / retry 5次 -> 可考慮延長時間及retry次數
2.增加logstash每次寫入DB的時間間隔
3.延長logstash等待連線時間:5s -> 30s
4.調高ES連線池總數量
5.更改SQL設計為,撈取PG 11/1-11/2資料,下一個排程撈取11/2-11/3資料,依此類推